
Artificial Intelligence is rapidly changing the world, affecting every aspect of our daily lives. From voice assistants using NLP and Machine Learning for making appointments in the calendar, and playing music to automatically suggesting products, so accurately that they can guess what we will need in advance. Amazing, isn't it? In this post, we will walk through some of the NLP insights and techniques used in commercial use cases.
What is Natural Language Processing?
Natural Language Processing (NLP) is itself a broad field that lies under Artificial Intelligence. NLP depends upon linguistics and is responsible for making computers understand the text and spoken words the same way humans do.
Natural Language Processing combines computational linguistics, rule-based modeling of human language with some statistics, machine learning, and deep learning to enable computers to understand the human language which can be in the form of text or voice data. The idea of NLP has been around for more than 50 years and it is now a rapidly growing field in the tech world with the rise of computers across the globe.
NLP-enabled software assists us in our daily lives in various ways, for example:
- Personal Assistants: Siri, Cortana, and Google Assistant
- Machine Translation: Google Translator
- Grammar check: Grammarly app
- Autosuggestion: In search engines, Gmail, Developer's IDE
What is NLP used for?
So, it is time to discuss the uses of Natural Language Processing and how it has evolved in the era of technology. The basic aim of NLP is not only to understand the single word to word but also to have the capability to understand the context based on syntax, grammar, etc of those words, sentences, and paragraphs to give the desired result out of it.
In short, NLP gives the machines the ability to read, understand, drive meaning from the text and often generate the text from various languages.
Let us take Gmail for example. When we compose an email we get suggestions of similar words, spelling mistakes, and autocompletion of sentences are also taken care of. Similar to this you may have heard of Grammarly application. It also uses similar NLP based techniques to offer the ability to automatically correct spelling and grammatical mistakes.
But How Does a Computer Understand Text?
Computers do not directly understand the words and sentences which belong to human languages. The computer only understands binary numbers as 0s and 1s. So we had to initially develop a way for computers to understand the words. Word representation is a widely used implementation for this problem. Word representation is a technique to represent a word with a vector and each word has its unique vector representation.
Text and word representation are essential for making computers understand words and thus we need to encode words into a format understandable by the computers. One-hot encoding is one such technique used to convert categorical data into numerical data. The numerical data is then used by the algorithms to learn and predict.
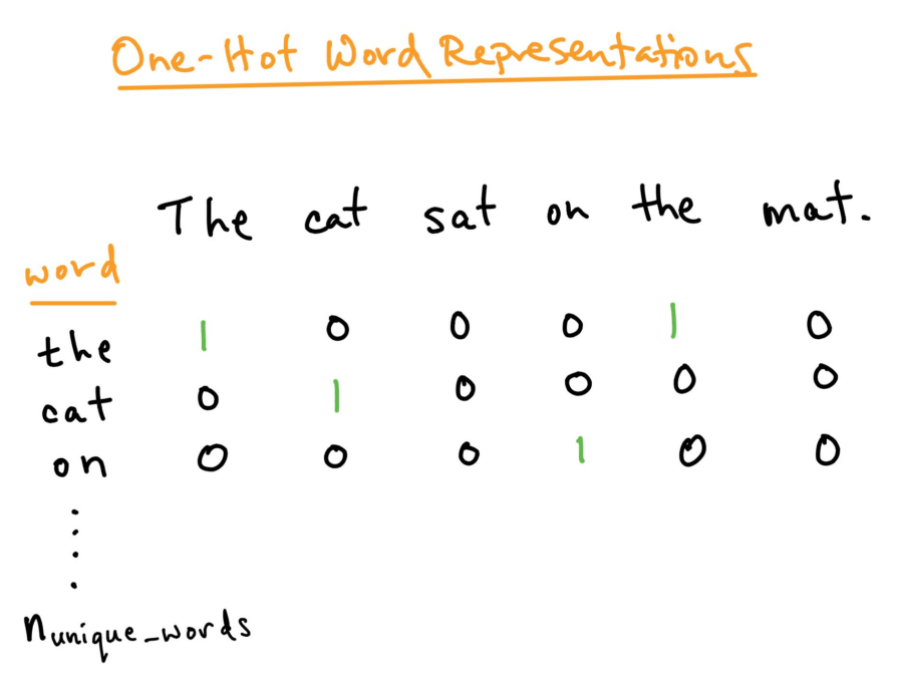
Source
Drawback: Memory capacity and lack of meaningful representation are two of the major challenges associated with this technique.
Here are some of the most popular word representation techniques:
- Count Vectorization
- TF-IDF Vectorization
- Hashing Vectorizer
- Word2Vec
NLP Tasks and Techniques
NLP tasks and techniques are frequently used to build NLP-based software. It helps to separate the human language into machine-understandable lumps and that can be used to build the NLP-based software.
Below mentioned are the tasks performed in an NLP process:
- Stemming
- Lemmatization
- Tokenization
- Stopwords removal
- Word Sense Disambiguation
- Part of Speech Tagging
Each of the above mentioned tasks have been explained with a brief introduction below:
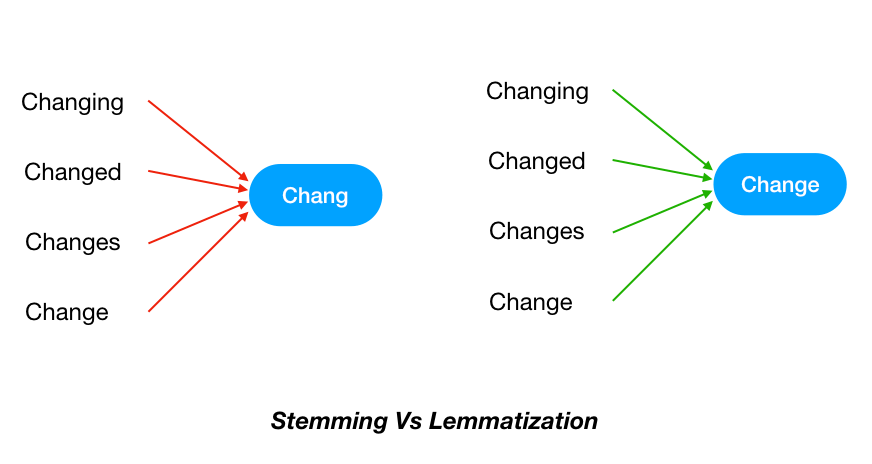
1. Stemming: Stemming is a process of reducing similar words to their stem word. The stem word could be either meaningful or meaningless.
For example:
- Finally, Final, Finalized - Final (meaningful)
- History, Historical - Histori (meaningless)
- Automates, Automatic, Automation - Automat ( meaningless)
- Wait, Waiting, Waits - Wait (meaningful)
2. Lemmatization: Lemmatization is the process of mapping words into their meaningful base structure. The main difference between stemming and lemmatization is:
Lemmatization converts the word to its significant meaningful base structure while stemming simply eliminates the last couple of characters which may or may not be meaningful.
3. Tokenization: Tokenization is the process of breaking a complete sentence into words and we can say that each word is a token.
For example, A sentence such as “Hope you are doing well ” has 5 tokens ie. Hope-you-are-doing-well. Likewise, tokens can be either characters or sub-words too.
4. Stopwords Removal: Stopwords are the most frequently used words in human language. Examples of stop words in English are “a”, “the”, “is”, “are”, etc. Stopwords do not contain valuable information or we can say they do not add much meaning to a sentence, so stop words can be ignored without affecting the meaning of the sentence. Similarly, every human language has its stopwords.
5. Word Sense Disambiguation: It is used to determine if the Same words can have different meanings in different sentences.
For example:
- The bull is running fast.
- According to Senex, the bull is running high.
- You should read this book, it has a great story
- You should book the flight as soon as possible
The same words "book" and "bull" have been used in the above examples for different contexts. Thus, word sense disambiguation is used to understand the context in which the word has been used in a sentence.
6. Part of Speech Tagging: Part Of Speech (POS) tagging is well-known in NLP, which is used to label each word in a sentence or it can be a paragraph with its appropriate part of speech. Part of speech includes verbs, adverbs, adjectives, pronouns, etc.
NLP Use Cases
In the 21st century, we all use NLP-based software and applications in our daily lives to assist us to perform our tasks, although most of us are unaware of this. Now it is time to shed some light on it.
Some of the most commonly used NLP uses cases are:
- Machine Translation (MT)
- Spam Detection
- Virtual Assistants and Chatbots
Let us now give you a quick rundown of each of them.
1. Machine Translation: Machine Translation simply refers to converting one human language to another based on context, grammar, etc. Google translator is the widely used software by Google to translate human languages. If you are a traveler, you must have used the google translator app.
2. Spam Detection: Spam detection implies recognizing messages or emails by understanding content, context altogether and move those messages or emails into spam envelopes so that you can avoid content that you do not like and also protect your privacy.
3. Virtual Assistants and Chatbots: Chatbots have a conversational UI (CUI) that empowers clients to speak with the chatbot by using textual messages. Virtual Assistants have a talk-like interface that enables users to speak and send their messages. Also in addition they can work without an interface when enacted utilizing voice orders. Chatbots and Virtual Assistant both work on NLP.
We are sure you must have gained a good understanding of Natural Language Processing and how it works. Now we will be proceeding towrads how NLP is used for Machine Translation.
Machine Translation
Machine Translation as discussed earlier, translates the meaningful text of one language to another language, with no human involvement. Machine Translation is evaluated on the BLEU(BiLingual Evaluation Understudy) score. BLEU is a metric for automatically evaluating machine-translated text. The score is between 0-1, the higher the score the better the machine translation.
Machine Translation has been present in the industry for several decades. Beginning in the 1970s, there were projects to achieve automatic translation. Over the years three major approaches have emerged:
- Rule-based Machine Translation (RBMT): 1970-1990
- Statistical Machine Translation (SMT): 1990-2010
- Neural Machine Translation (NMT): 2014-Present
Rule-based Machine Translation (RBMT): 1970-1990
RBMT systems are built on linguistic principles that allow words to be put in multiple locations and have varied meanings depending on the context. The RBMT approach is applied to the following language rules: transfer, analysis, and creation. Human language experts and programmers develop these rules.
Advantages:
- You do not need bilingual text
- Complete control (new law applicable in all cases)
- Reusable (existing language rules can be transferred when paired with new languages)
Disadvantages:
- Need good dictionaries
- Manually set rules (requires expertise)
Statistical Machine Translation (SMT): 1990-2010
SMT (Statistical Machine Translation) mainly uses or gets trained on existing human translation known as bilingual text corpus. As we have seen above the RBMT system mainly focuses on word-based translation but the SMT system focuses on phrase-based translation. The goal of phrase-based translation is to remove the constraints of word-based translation by translating entire sequences of words of varying lengths. The word sequences are called phrases, however, they are generally not linguistic phrases, but rather phrases discovered using statistical approaches from bilingual text corpora.
Advantages:
- One SMT is suitable for two languages.
- Offline translation without a dictionary: with a proper language model, the translation is very smooth.
Disadvantages:
- Requires a bilingual corpus
- It is not appropriate for pairs of languages that have significant differences in word order.
Neural Machine Translation (NMT): 2014-Present
NMT is a popular and widely used translation service that incorporates an end-to-end approach for automatic translation which overcomes the weaknesses of RBMT and SMT methods. NMT uses the most recent deep learning methods to produce better translation output than other traditional Machine Translation solutions. It is the most recent type of machine translation that employs a neural network that is closely related to the neurons of the human brain, allowing it to categorize data into various groups and layers. NMT is a language translation approach that tries to incorporate the context of the sentences or paragraphs rather than individual words. The NMT system is made up of current multilingual databases and automated learning mechanisms that contribute to continuous improvement.
Advantages:
- End-to-end models (no pipeline of specific tasks)
Disadvantages:
- Requires a bilingual corpus
- Sometimes unable to resolve unfamiliar words.
Machine Translation Algorithms & Models
Without Encoder-Decoder models, Machine Translation algorithms would not exist or could not give better translations. Language translation models based on encoder-decoder machine translation have had a lot of success.
Mentioned below are some state-of-the-art models with an explanation of what encoder-decoder models are like:
- Attention is all you need
- Bidirectional Encoder Representation from Transformers (BERT)
- Generative Pre-trained Transformers (GPT)
Attention is all you need
"Attention is all you need" was proposed in 2017 and this was a huge breakthrough in the evolution of deep learning. The whole model architecture depends upon the attention mechanism. The architecture generally has an encoder-decoder structure. The encoder maps an input to generate the embedding with positional encoding and most importantly the attention mechanism. The decoder then generates an output with the help of a feed-forward neural network. The attention mechanism gives the flexibility to introduce more parameters to generate more features or relations between the data.
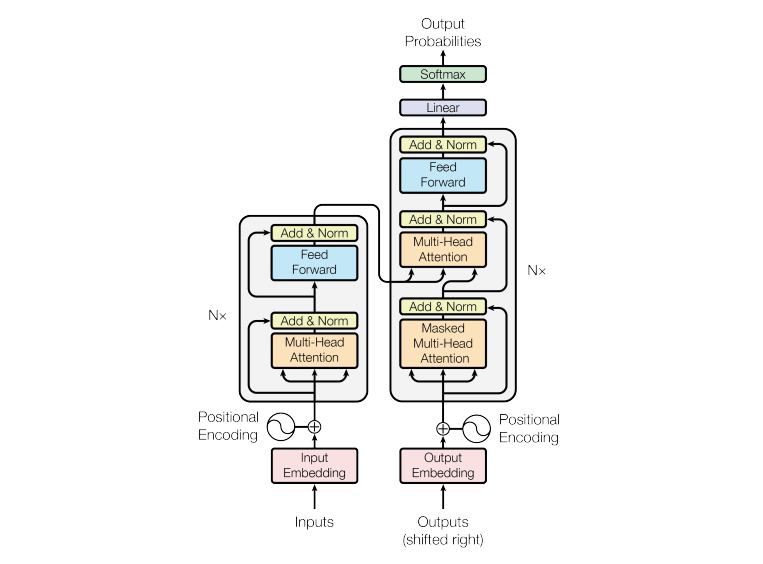
Source
Encoder: In the above figure, the encoder is in the left which is composed identically in a stack of 6. The encoder has two sub-layers in each of them ie. multi-head attention with addition and normalization operation and another is a simple feed-forward network with addition and normalization operation with the skip connection between them.
Decoder: In the above figure, the right side is the decoder which is composed identically in a stack of 6. The decoder has three sub-layers, the two are identically the same as the encoder, the other layer is masked multi-head attention.
Bidirectional Encoder Representation from Transformers (BERT)
As the name suggests Bidirectional Encoder Representation from Transformers is an encoder-based architecture. The BERT model is based on the attention is all you need model, this is the reason “Attention is all you need” is the huge breakthrough in the evolution of deep learning. The BERT model can understand the meaning of complicated human languages in the text and perform various tasks like Machine Translation, Text Summarization, etc with a higher BLEU score and higher accuracy respectively.
BERT is a cutting-edge NLP model created by Google AI. BERT can understand the text in both directions and this operation is known as bi-directionality. BERT has also proposed Masked Language Model (MLM) training to hide some of the parts in the input, the learning or training of the model to predict the missing tokens.
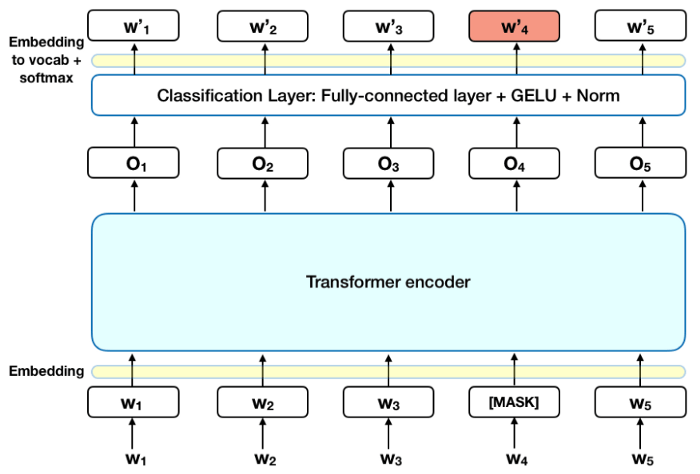
Source
Google Neural Machine Translation (GNMT)
Official Research Paper
The power of GNMT lies in its ability to read directly in the form of an end-to-end and map from input text to corresponding output text.
Its construction typically consists of two duplicate neural networks (RNNs), one to use input text sequences and one to produce translated text.
XLM model by Facebook
Official Github
Official Research Paper
XLM-R (New Model)
XLM-R is Facebook AI's latest cutting-edge XLM model for Machine Translation. XLM-R is a strong model that demonstrates the ability to train a single model for many languages while maintaining per-language performance. It has been trained on 2.5 TB of Common Crawl data in over 100 languages.
Generated Pre-trained Transformer (GPT)
You must have heard of the GPT category of language models, it has been developed by OpenAI. This phase, which includes the development of GPT-2 and GPT-3, has been attracting worldwide attention as they have been able to produce text similar to human-written text. As we have seen BERT is an encoder-based architecture based on transformers and GPT is a decoder-based architecture based on transformers. Both BERT and GPT are based on the “Attention is all you need” model. The full version of GPT-3 has 175 billion trainable parameters. GPT-3 can create poetry, articles, dialogues, stories, and it only needs a small amount of input text in the English language. GPT-3 also can create executable code for developers by just passing English text as input.
Multilingual Models Resource
Here you can find a good variety of multi-lingual models, pre-trained or tuned for several machine translations tasks and languages.
Most of the multi-lingual models in the above mentioned link are state-of-the-art models with a high BLEU score
Benefits of Machine Translation
1. Time efficient: Machine Translation models can save a significant amount of time as they can translate a whole document in sec.
2. Cost efficient: It does not require human involvement which leads to lower cost.
3. Memorizes terms: Machine Translation models are designed in such a way that they memorize the key terms and reuses them wherever they fit.
Final Words
The sky is the limit when it comes to natural language processing. As technology becomes more widespread and greater advancements are explored, the future will see some major shifts in this domain. We hope this post helps you gain a better understanding of the NLP ecosystem as a whole.